







We Forge
Digital Experiences
From custom web design to AI-powered business tools, we craft digital solutions that transform how businesses connect with their customers. Every pixel forged with purpose.
Forged for Your Vision
17+ years of crafting digital solutions — from stunning websites to AI-powered tools that work while you sleep.

Web Design
Custom websites built from the ground up. No templates, no shortcuts — every site forged to fit your brand.

E-Commerce
Shopify, WooCommerce, Magento — we build stores that convert. Payment processing, inventory, the works.

AI & Innovation
DraftDash, MOG, Ethel, Thea, Katori — our AI suite automates what used to take hours.
Graphic Design
Logos, branding, print materials, photography, and video production — your visual identity, forged.

Internet Marketing
SEO, SEM, social media, content creation — we put your brand in front of the right audience.
Forged Sites
Hand-coded sites you fully own — liftable, portable, no page-builder lock-in. Take it anywhere, any time.
Platforms We Build & Maintain
 WordPress
WordPress
 Shopify
Shopify
 WooCommerce
WooCommerce
 Magento
Google Ads
Semrush
Cloudflare
Magento
Google Ads
Semrush
Cloudflare
The IDFS.AI Suite
We didn't just learn AI — we built an entire ecosystem of tools that work for your business 24/7.


Fresh from the Forge
Live forged sites with real, dated PageSpeed scores — click any project to see the full story.
Lions Services
Nonprofit — Blind Services
Happiness Card Game
Tabletop Gaming
Clark's Tree Care
Tree Care & Arborist Services
The Closet Rehab
Custom Closets & Home Storage

Mr. Outdoor Living®
Outdoor Living Design & Build
Beach Insurance
Insurance — Coastal Carolinas
Cornerstone Insurance
Insurance — Inland Carolinas
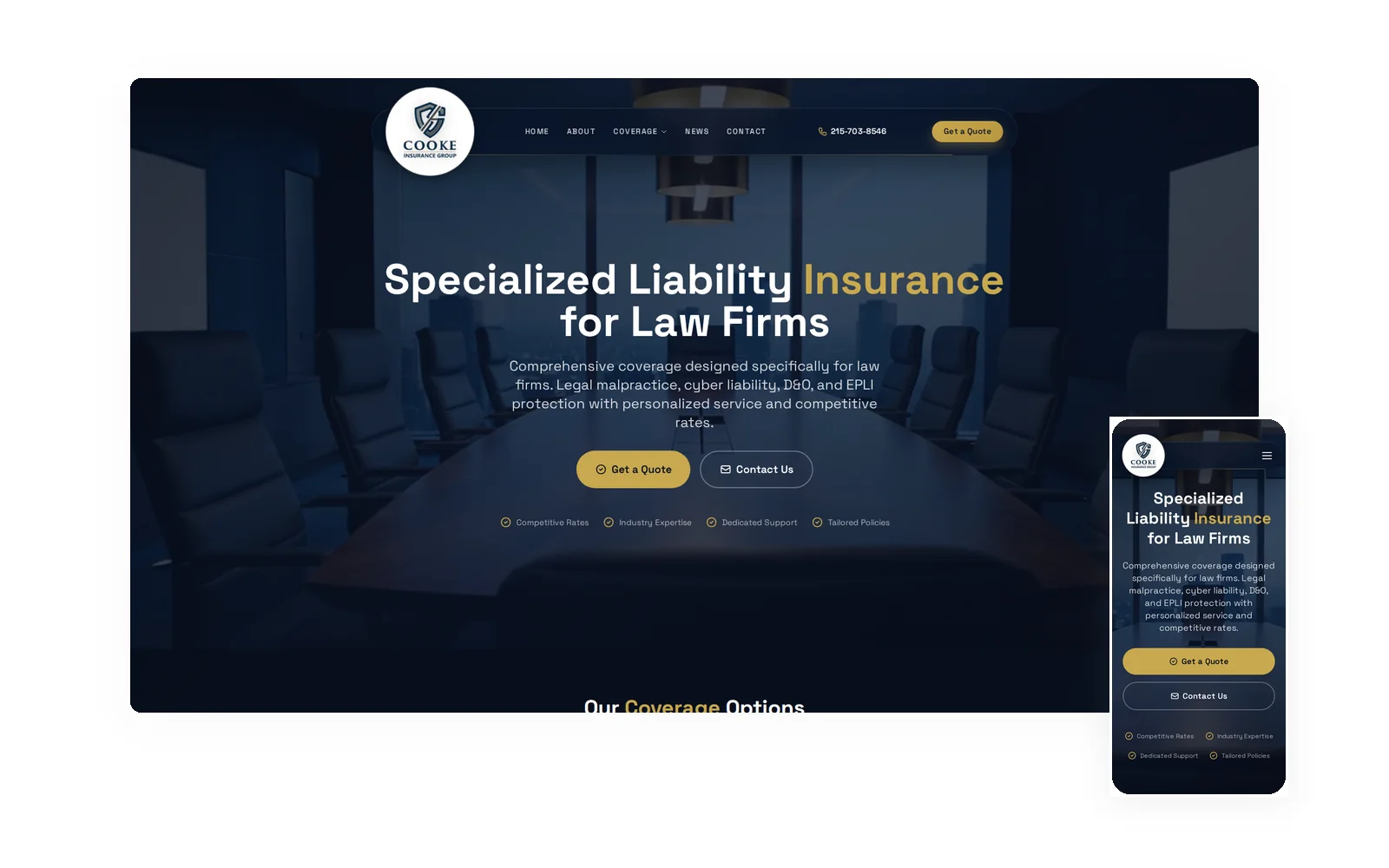
Cooke Insurance Group
Legal Professional Liability Insurance
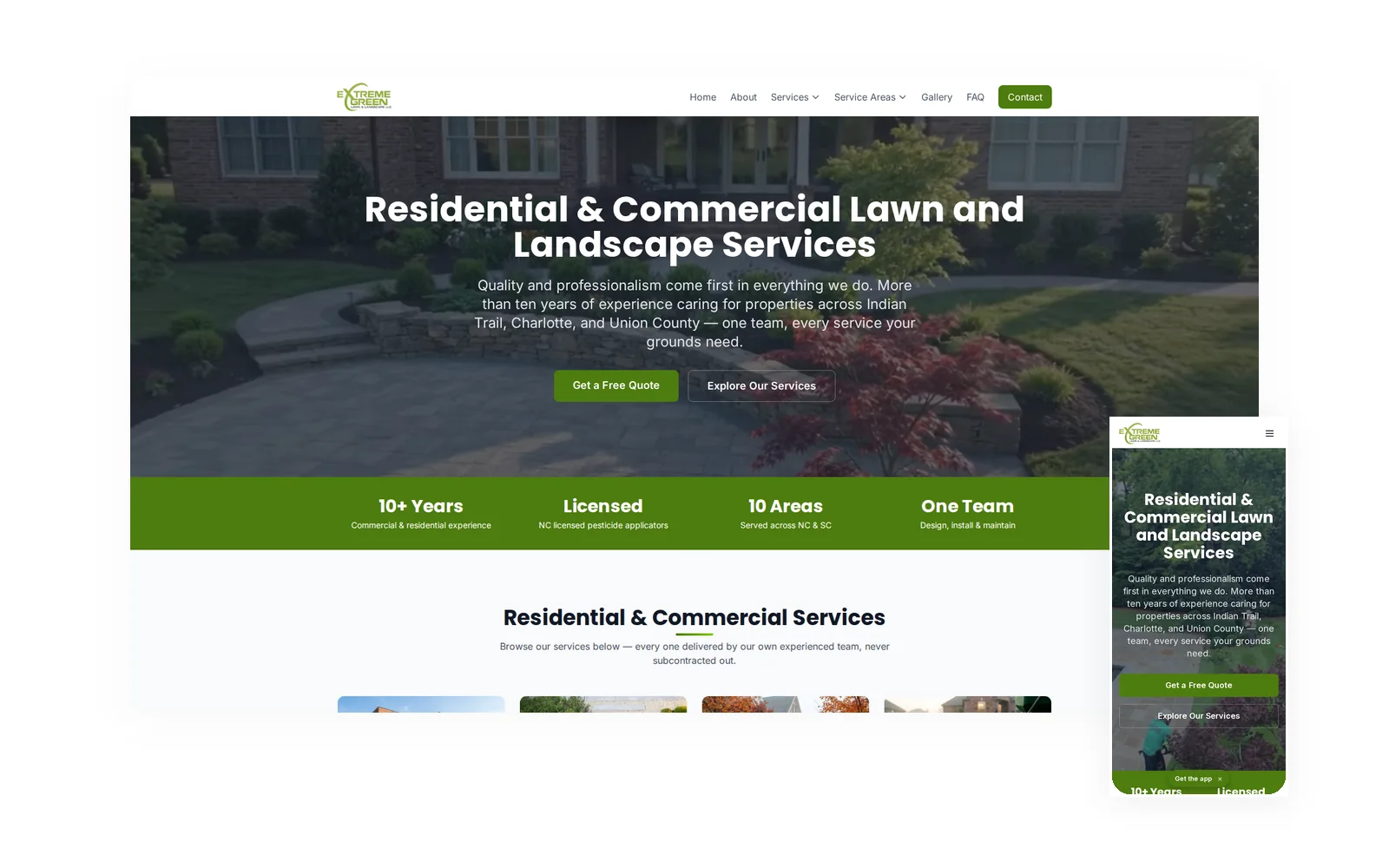
Extreme Green Lawn & Landscape
Lawn Care & Landscaping
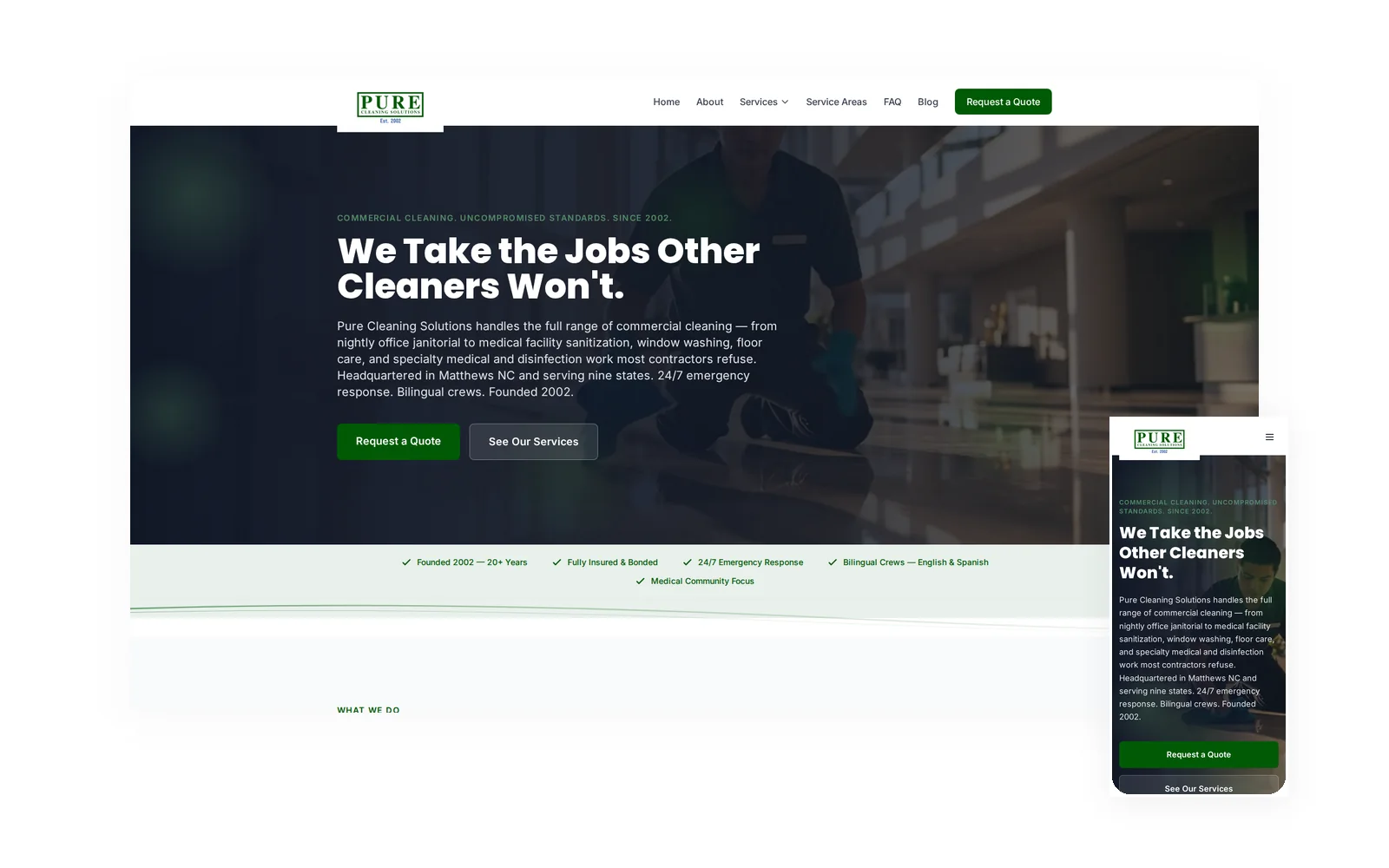
Pure Cleaning Solutions
Commercial & Medical Cleaning
Ready to Forge Something Amazing?
Whether you need a stunning website, a powerful e-commerce store, or AI tools that automate your business — we're ready to build it.